Конфигурационный файл chatbot.yaml
chatbot.yaml — конфигурационный файл чат-бота. Файл содержит основную информацию о конфигурации проекта, например:
- имя главного файла сценария;
- данные о подключаемых зависимостях;
- конфигурацию NLU;
- перечень файлов с тестами.
В данном разделе перечислены настройки, которые можно задать в chatbot.yaml, и их назначение.
Точка входа в сценарий
entryPoint: main.sc
Поле используется для указания файла, с которого начинается загрузка сценария чат-бота при публикации.
Файл должен находиться в папке src и обычно называется main.sc или entryPoint.sc.
require.entryPoint — обязательное поле.Имя бота
name: echo-bot
Поле задает имя бота, которое будет использовано, например, в сообщениях о публикации бота в канал. Если поле отсутствует, в качестве имени используется системное название проекта.
Настройки NLU
Диалоговый движок
botEngine: v2
Поле задает версию диалогового движка бота.
v2 позволяет использовать для понимания естественного языка (NLU) сервис CAILA.
Это рекомендуемое значение поля для всех новых проектов.v2, будет использован движок первой версии v1.
NLU на этом движке возможен только при помощи паттернов.Язык бота
language: ru
Поле задает язык, на котором общается бот. Значение поля должно быть ISO-кодом нужного языка.
Пороговые значения классификатора
nlp:
intentNoMatchThresholds:
phrases: 0.2
patterns: 0.2
Поля phrases и patterns в секции nlp.intentNoMatchThresholds задают пороговые значения для классификатора интентов CAILA и его гипотез.
Рассмотрим поведение классификатора интентов:
- Пользователь отправляет запрос боту.
- При формировании гипотез классификатор сравнивает запрос с паттернами и тренировочными фразами по отдельности. Он вычисляет вероятность для каждой из гипотез.
- Если вероятность гипотезы меньше, чем порог у
phrasesилиpatterns, эта гипотеза не учитывается при дальнейшей обработке запроса и определении стейта в сценарии.
Таким образом, intentNoMatchThresholds задает минимальную похожесть запроса на фразы или паттерны.
Чем ближе значение к 1, тем строже классификатор и тем более точные требуются совпадения.
Значение phrases и patterns по умолчанию — 0.2.
Это значение используется, если не задать другое для любого из полей.
nlp использовалась секция caila.
Она содержит поле noMatchThreshold, которое задает общее пороговое значение и для фраз, и для паттернов.
В новых проектах для корректного определения паттернов рекомендуется использовать вместо нее секцию nlp,
поскольку у классификатора и алгоритма, который вычисляет вес паттернов, могут быть разные шкалы.Длина $context.nBest
nlp:
nbest: 3
nbestPatterns: 1
nbestIntents: 2
nbestExamples: 3
Поля семейства nlp.nbest задают число правил активации,
к которым можно получить доступ из сценария через объект $context.
- Поле
nbestзадает длину$context.nBest— массива сработавших для запроса правил активации всех типов: паттернов, интентов и примеров. Значение по умолчанию —1. - Поле
nbestPatternsзадает длину$context.nBestPatterns— массива правил активации, сработавших только при помощи паттернов. Если поле не указано, то этот массив недоступен.
nbestIntents и nbestExamples работают аналогично для интентов и примеров.
Ограничения при обработке запроса
Ограничение на длину запроса
nlp:
lengthLimit:
enabled: true
symbols: 100
words: -1
Секция nlp.lengthLimit задает ограничение на длину запросов, которые принимает бот:
enabledвключает или выключает проверку.symbols— максимальное количество символов в запросе.words— максимальное количество слов в запросе. Если указано-1, эта проверка не производится.
По умолчанию включено ограничение на 400 символов, ограничение на количество слов отключено.
lengthLimit.Ограничение на время обработки запроса
nlp:
timeLimit:
enabled: true
timeout: 500
Секция nlp.timeLimit задает ограничение на общее время, в течение которого будет обработан запрос:
enabledвключает или выключает проверку.timeout— максимальное время обработки запроса в миллисекундах.
По умолчанию ограничение включено со значением таймаута 10000 (10 секунд).
timeLimit.XML-тесты
tests:
include:
- "authorization.xml"
- "integration-tests/*.xml"
exclude:
- "broken.xml"
caseSensitive: false
XML-тесты сценариев позволяют проверить логику чат-бота, эмулируя запросы клиента и проверяя ответы от бота.
По умолчанию выполняются все тесты из файлов в папке проекта test.
Это поведение можно переопределить в секции tests, задав значения для подсекций include и/или exclude:
include— будут выполнены тесты только из тех файлов, которые попадают под шаблоны, перечисленные в этой подсекции.exclude— из выполнения будут исключены все файлы, которые попадают под шаблоны, перечисленные в этой подсекции.
Поле caseSensitive определяет, должны ли шаблоны учитывать регистр названий файлов. Значение по умолчанию — true.
Зависимости
dependencies:
- name: common
type: git
url: https://<repository>
version: heads/master
Секция dependencies позволяет задать список зависимостей проекта.
Теги действий
customTags:
- src/blocks/SumTwoNumbers/block.json
Секция customTags задает список самостоятельно созданных тегов действий, которые используются в проекте.
Пользовательские реакции
customBlocks:
- src/blocks/video.json
Секция customBlocks задает список пользовательских реакций, которые используются в рассылках.
Сообщения об ошибках
messages:
onError:
locales:
ru: Что-то пошло не так.
en: Failed on request processing.
defaultMessage: Что-то пошло не так.
# defaultMessages:
# - Извините, что-то сломалось.
# - Произошла ошибка при обработке запроса.
Секция messages.onError позволяет задать текст сообщения, которое бот отправит при возникновении какой-либо ошибки.
В подсекции locales могут быть заданы тексты сообщений, локализованные исходя из данных о пользователе.
В данной подсекции ключи представляют собой ISO-коды языков, а значения — тексты сообщений.
В поле defaultMessage указывается текст сообщения по умолчанию,
которое отправляется в случае, если секция locales не задана или в ней не задан нужный язык.
Также можно задать список сообщений по умолчанию в поле defaultMessages — тогда при ответе будет выбрано случайное из них.
messages.onError не заполнена, то в случае возникновения ошибки бот не ответит клиенту.Injector
injector:
catchAllLimit: 10
api:
protocol: https
host: example.com
port: 443
Секция injector позволяет задать параметры конфигурации чат-бота.
Заданные параметры будут доступны в скриптах чат-бота через переменную $injector.
Настройки SMTP-сервера
Секция injector.smtp позволяет задать настройки SMTP-сервера,
через который будут отправляться email-сообщений при помощи метода $mail.sendMessage.
injector:
smtp:
host: smtp.just-ai.com # Хост SMTP-сервера
port: 2525 # Порт SMTP-сервера
user: user@just-ai.com # Пользователь SMTP-сервера
password: qwerty # Пароль от SMTP-сервера
from: bot@just-ai.com # Отправитель email-сообщения
# Необязательные поля
hiddenCopy: admin@just-ai.com # Получатель скрытой копии email-сообщения
# Можно передать список получателей:
# hiddenCopy:
# - admin@just-ai.com
# - support@just-ai.com
debugMode: true # Включен или выключен режим отладки
Другие настройки
Возможность изменения запроса
nlp:
modifyRequestInPreMatch: true
Поле nlp.modifyRequestInPreMatch включает возможность изменять содержимое запроса в обработчике preMatch — например, редактировать текст запроса.
Токенизация слов в паттернах
tokenizeWordsInPatterns: true
Поле tokenizeWordsInPatterns включает токенизацию слов в паттернах для языков без разделителей между словами.
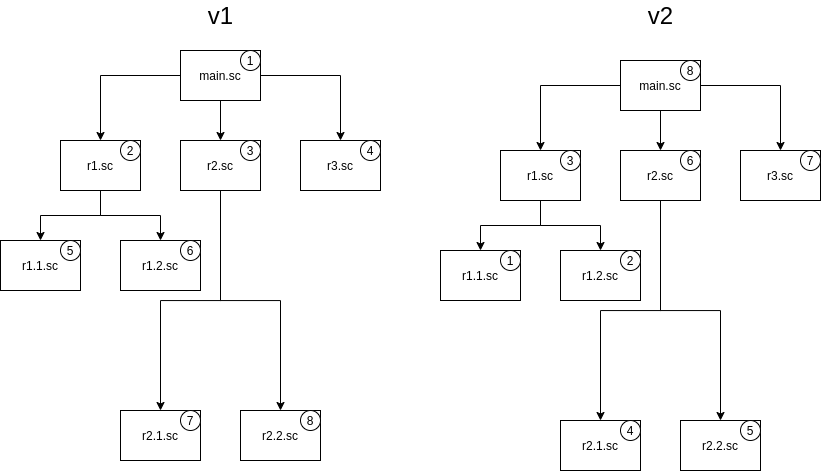
Порядок загрузки файлов
scenarioLoadStrategy: v2
Поле scenarioLoadStrategy задает порядок загрузки файлов в сценарий, состоящий из множества файлов.
Поле имеет два возможных значения: v1 (значение по умолчанию) и v2.
При стратегии v1 загрузка производится в порядке сверху вниз по дереву импортируемых файлов, а при v2 — снизу вверх.
Рассмотрим пример.
В файл main.sc при помощи тега require импортируются файлы r1.sc, r2.sc и r3.sc, в файлы r1.sc и r2.sc также импортируются по два файла.
При публикации сценария файлы будут загружены в порядке, приведенном на изображении.
Влияние расстояния до стейта на вес интента
nlp:
considerContextDepthInStateSelectionV2: false
Поле nlp.considerContextDepthInStateSelectionV2 определяет,
учитывается ли контекстное расстояние до стейта, сработавшего по тегам intent/intent! или intentGroup/intentGroup!,
когда рассчитывается вес совпадения по интенту.
true(значение по умолчанию) — расстояние до стейта учитывается при расчете веса интента и при выборе стейта, в который нужно перейти.false— вес интентов не зависит от расстояния до стейта и рассчитывается одинаково во всех стейтах сценария.